Import PDF Tables in Power BI & Python
One of the best things that have happened to Power BI is the addition of Python scripting options. There are a host of things that can be accomplished such as data imports, custom Python visuals, and advanced data cleansing. For this tutorial, I am going to show you how to import PDF tables into Power BI with the help of Python. You will be able to do this with 2 lines of code!
Prerequisites:
You will need to have Python installed on your PC. If you haven’t done so, I highly recommend using the Anaconda installation package. This is a very simple way to keep your Python modules maintained. You will also need to load install Tabula.
You can install Tabula by simply using the following line in your Anaconda Prompt. Check out how to install Anaconda.
conda install -c conda-forge tabula-py
Before getting started. I wanted to give you non-python users some quick context to what we are doing. Tabula is a Python library that allows you extra tables from a PDF. The read_pdf function from tabula has several arguments for the first test we just need to enter the path of where you have saved the PDF. This will pull in the table from the first page of the PDF
In order for this function to load the table in question, you need to save it as a variable. I am going to use the word “data” to save it as. So you would save it as shown below:
data = read_pdf('C:\\...pdf')
How to Load PDF Tables into Power BI with Python
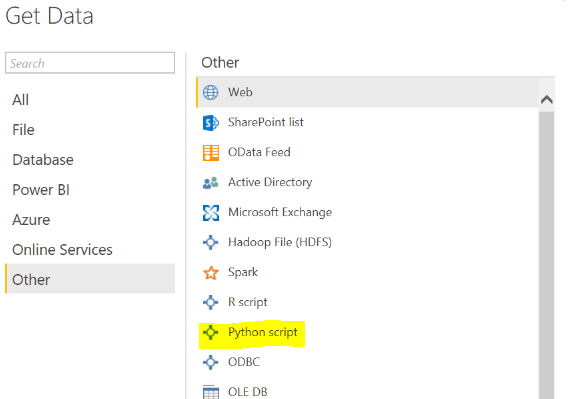
- Click Get Data
- Navigate to the Python Script (Get Data > More > Other > Python Script) or simply type “python” in the search bar after clicking More.
- Once initiating, you will get the scripting window.
- Simply copy the following text into your the scripting window.
-
from tabula import read_pdf
-
data = read_pdf('C:\\Users\science.pdf')
-
- Choose the table and import into the data model.


What if your PDF table is not on the first page?
To pull in a table that is not on the second page you simply need to add one more argument to your function. This is the “pages” argument. You can simply add this after the path argument.
data = read_pdf('C:\\Users\science.pdf',pages='2')
This will allow you to bring the table that is located on the second page of your PDF report.
What if you have multiple tables on a single page?
If you have multiple tables on a single page, to bring in each of those tables requires you to use the “mutiple_tables=True” argument in your function. The second requirement is that you name each table with a variable. For example, if I have 2 tables on page 2, the code would look like the following:
data,data2 = read_pdf('C:\\Users\science.pdf',pages='2',multiple_tables=True)
This would present two tables named data and data2

[…] Download Image More @ http://www.absentdata.com […]